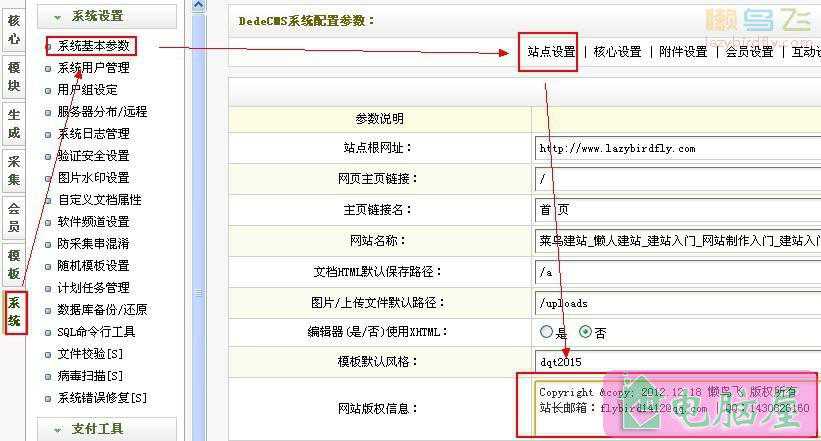
写关关采集规则时获得目录部分关键HTML的设置,截取时用正规代替换行!
作者:admin 时间:2019-11-30 阅读数:119人
在写关关采集时如果出现重复章节,一般情况是最新九章节和所有章节的代码是一样的,关关是不会自动排重的时候要用到
意思是要通过PubVolumeContent里去截取正文章节的范围,这样就可以直接采集所要的内容
但一般很不容易截取,所以要用到正则表达式来截取

上述为例,如果截取,只能是
而且正文卷这三个字我在写规则的时候发现也在变化
所以这种网站唯一的规则是
意思是要通过PubVolumeContent里去截取正文章节的范围,这样就可以直接采集所要的内容
但一般很不容易截取,所以要用到正则表达式来截取
上述为例,如果截取,只能是
但这样却不能真正截取到,因为最新九章节也是这样的规律<dt>.+?</dt>((.|/n)+?)</div>
而且正文卷这三个字我在写规则的时候发现也在变化
所以这种网站唯一的规则是
对,用/n+?,因为直接用.+?不行,因为有换行,所以加上/n,最后终于可以采集到截取的正文章节了!</dd>/n+?<dt>.+?</dt>((.|/n)+?)</div>
声明
源码下载不顺利,比如源码在百度网盘的有时会被无故取消等,请联系QQ:46667551
本站大部分下载资源收集于网络,但除特别说明之外,基本全部亲自测试可用!
但由于某些源码的更新迭代,比如微信小程序官方接口的变动等原因,
如时间过长,可能会造成本可以使用的代码出现问题,下载前请斟酌!
本站资源仅供学习和交流使用,版权归原作者所有,请在下载后24小时之内自觉删除。
若作商业用途,请购买正版,由于未及时购买和付费发生的侵权行为,使用者自行承担,概与本站无关。
原文链接:https://www.dnwfb.com/271.html,转载请注明出处